
[Paper Review] DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases
DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases”, ICLR 2023 poster. All figures are captured from the paper.
TL;DR
DecAF, a novel KBQA framework, simultaneously generates both logical forms and direct answers for a given question and combines them to decide the final answer. By preventing a decrease in querying ability caused by non-executable logical forms, DecAF achieves state-of-the-art accuracy on WebQSP, Freebase, and GrailQA benchmarks.
Knowledge-Based Question Answering (KBQA)
KBQA is the task of answering the natural question by accessing knowledge bases. Methods in KBQA is commonly divided into two categories, that are information retrieval-based (IR-based) and semantic parsing-based (SP-based). The former approach retrieves question-related entities or query graphs from KBs and ranks them to generate final answer, while the latter approach translates natural questions into logical forms (LF), such as SPARQL queries or S-expressions.
Unlike previous methods, in this paper, DecAF employs both IR-based and SP-based methods to generate final answers.
DecAF Method
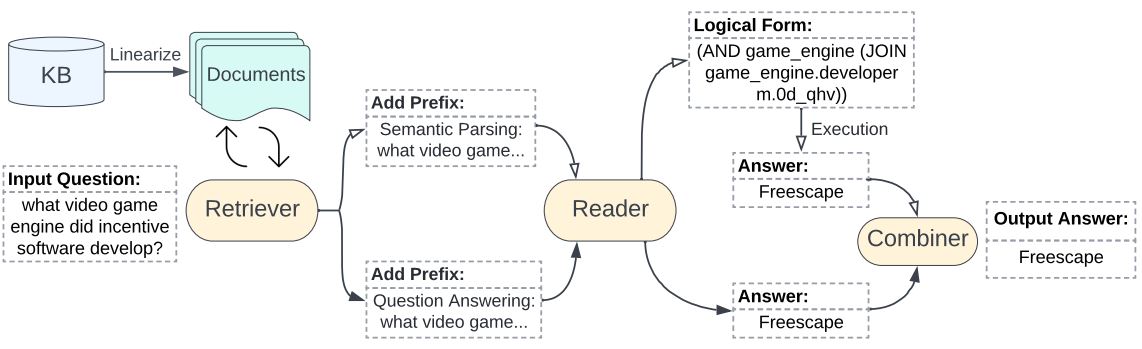
The framework is divided into following four steps:
1) Linarization: Convert the KB to documents.
2) Retrieval: Retrieve passages relevant to the question.
3) Reading: Generate a logical form (LF) and direct answers based on the question and retrieved passages.
4) Combining: Combine the LF and direct answers to determine the final answer.
Linearization
Instead of using a large and complicated KB, it is easier to retrieve relevant information from documents. Therefore, authors convert the KB into documents by concatenating compositions in triplets with spaces. Here is an example:

Then, sentences with the same head (Freecase in the above example) are grouped into the same document, preserving the structural information of 1-hop subgraph.
Retrieval
To retrieve question-related passages, two retrieval methods are considered: BM25 for sparse retrieval and DPR for dense retrieval.
- BM25 utilizes TF-IDF scores of the question and passages.
- DPR encodes the question and passages. Based on the dot product similarity between question and the passages, top-k similar passages are retrieved using FAISS.
Reading
The reader, which is a seq2seq model, generates the answer based on questions and retrived passages. To answer multi-hop questions, cross-passage reasoning is required. To achieve this, the reading process is designed as follows:
1) Encode the question and each passage:
\[\textbf{P}_{i} = \text{Encoder}(\text{concat}(\mathcal{q}, \mathcal{p_{r_{i}}}))\]2) Decode embeddings of all passage after concatenating them:
\[T_{output} = \text{Decoder}([\textbf{P}_1; \textbf{P}_2; \cdots; \textbf{P}_{|\textbf{I}_{retrieve}|}])\]By employing multi-task learning, the single reader can generate both logical forms and direct answers to the question. These two tasks are differentiated by prompting the model with different prefixes:
\[\textbf{P}_{i}^{answer} = \text{Encoder}(\text{concat}(\text{prefix}^{answer}, \mathcal{q}, \mathcal{p_{r_{i}}})), T_{answer} = \text{Decoder}([\textbf{P}_1^{answer}; \textbf{P}_2^{answer}; \cdots; \textbf{P}_{|\textbf{I}_{retrieve}|}^{answer}]);\] \[\textbf{P}_{i}^{LF} = \text{Encoder}(\text{concat}(\text{prefix}^{LF}, \mathcal{q}, \mathcal{p_{r_{i}}})), T_{LF} = \text{Decoder}([\textbf{P}_1^{LF}; \textbf{P}_2^{LF}; \cdots; \textbf{P}_{|\textbf{I}_{retrieve}|}^{LF}])\]Combining
Before determining the final answer, the generated logical forms are executed against the KB. This yields a list of executed answers and the list of directly generated answers.
If the executed answer does not exist, then the final answer becomes the direct answer with the highest score. Otherwise, two scores of each answer are combined, i.e. $\lambda S(i) + (1-\lambda) S(j)$, where i-th executed answer and j-th direct answer are the same, and $0\leq\lambda\leq 1$. The final answer is determined by ranking the combined scores.
Experiments
Settings:
- KB: Freebase (entities: 88 million, relations: 20k, triplets: 472 million)
- Retriever: BM25 implemented by Pyserini and DPR with BERT-base
- Reader: FiD-large and FiD-3B
- Dataset: WebQSP, ComplexWebQuestions (CWQ), FreebaseQA, and GrailQA
- Metric: Hits@1 and F1
Main Results
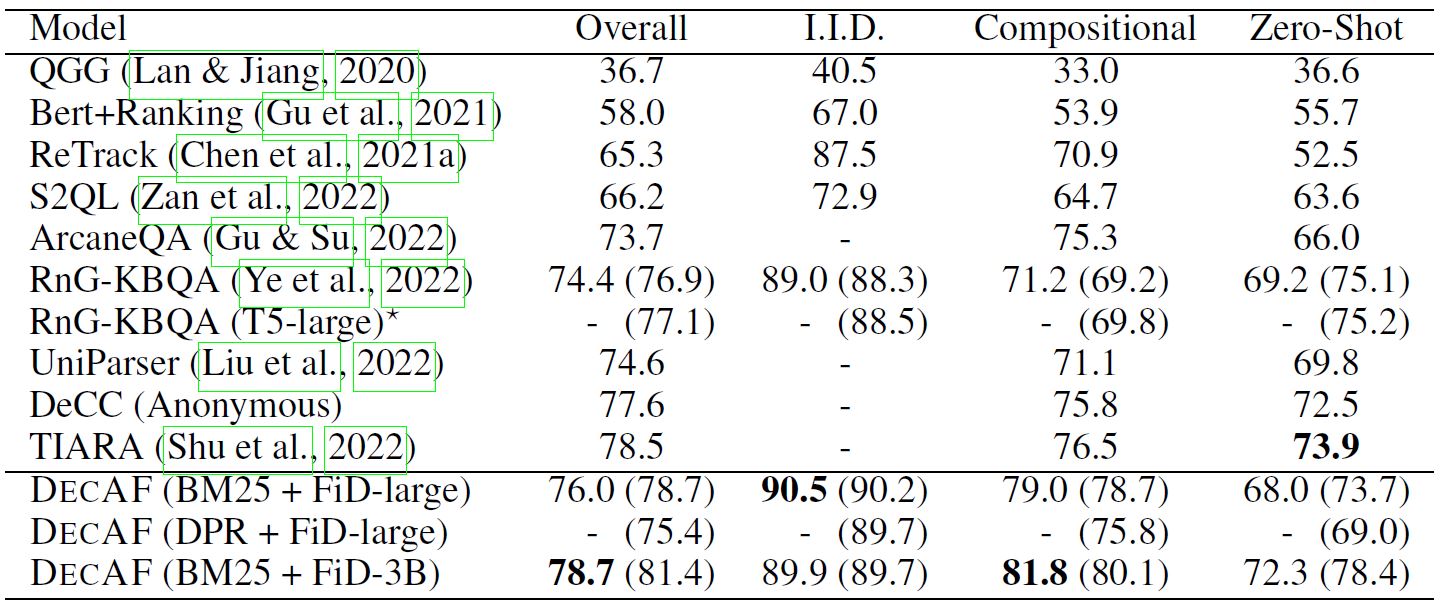
DecAF achieves a new SOTA performance on WebQSP and FreebaseQA datasets and very competitive results on CWQ dataset. The figure below shows F1 scores on the test split of GrailQA.
Ablation Study
The results of ablation study are interesting, and here are two summarized findings among five experiments:
- LF-executed answers are much more accurate compared to generated ones, i.e. direct answers.
- However, combining these two answers is significantly more effective than using either of them separately.
Conclusion
- DecAF is a novel framework that generates both logical forms and direct answers for KBQA.
- It is the new SOTA on WebQSP, FreebaseQA, and GrailQA datasets.
References
[1] Yu, Donghan, et al. “Decaf: Joint decoding of answers and logical forms for question answering over knowledge bases.” ICLR (2023).
Leave a comment